Archive
Análise de participação nos encontros do IETF
Introdução
Há imenso interesse em saber como tem sido a participação da América Latina nas reuniões do Internet Engineering Task Force (IETF), que acontecem três vezes ao ano. Desde o encontro do IETF 72 (27 de julho a 1 de agosto de 2008) realizado em Dublin tem estado disponível os participantes de cada encontro. A URL de acesso a estas informações é padrão e coincide com a do IETF 100, a ser realizado em Singapura em 11-17 de dezembro de 2017, onde somente o número pode ser trocado para atingir o encontro desejado, como ilustra a Figura 1.
 Figura 1. URL padrão dos encontros do IETF
Figura 1. URL padrão dos encontros do IETF
A aparência da página mudou ao longo do tempo, mas não de forma radical, como se pode ver na Figura 2 observando o cabeçalho da tabela contida nos encontros 72 e 100, respectivamente.
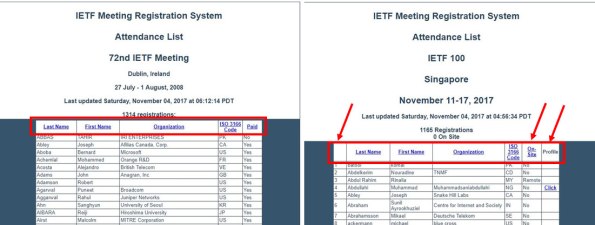
Figura 2. Visões dos encontros podem ser diferentes, como se pode ver nas páginas dos encontros IETF 72 e IETF 100, respectivamente.
Na página do encontro IETF 100, também aparece a referência “0 on Site“, o que não acontece na do IETF 72. Estas diferenças podem ocorrer em outros momentos sugerindo um cuidado especial no desenvolvimento de um processo automático para obter todos os dados, inclusive dos próximos encontros.
Adicionalmente, os recursos aqui tratados serão utilizados na construção do wordIETF, um repositório léxico, semântico e de bases de dados de aprendizagem para o projeto SKAU, ambos já comentados aqui no blogue e que serão revistos oportunamente.
Como automatizar o processo de captura dos dados
Existem várias formas de fazer isto. Várias técnicas e inúmeras linguagens. neste texto será usada a linguagem Python 3 e a facilidade do módulo Beautiful Soup1,2. Trata-se de uma escolha pessoal, que recaem, entretanto, sobre ferramentas universais. Colaboradores com habilidades mais apropriadas podem aperfeiçoar o que está sendo apresentado pois o material (dados e programas) estão disponíveis no GitHub, https://github.com/juliaobraga/ietf, com este propósito.
Python e Beautiful Soup são ferramentas muito utilizadas e estão disponíveis na Internet com detalhes surpreendentes e não iremos nos preocupar em ensinar nenhuma das duas ferramentas. Apenas faremos comentários úteis sobre algumas facilidades disponíveis na Beautiful Soup.
Primeiros passos
Inicialmente será analisado o código HTML destas páginas, partindo da premissa que não há diferença entre elas, por enquanto. O código IETF01 da Figura 3 mostra a leitura e gravação do conteúdo da página do IETF 100, usando o “requests” como visto na linha 1.
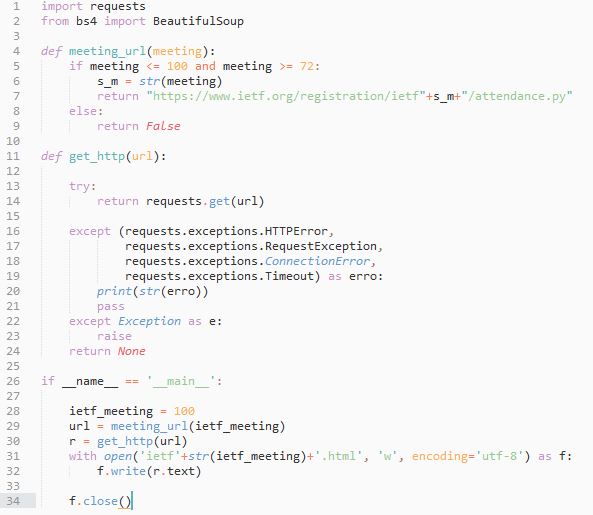
Figura 3. Código 01: usando o requests para ler o conteúdo HTML da página de inscritos no IETF 100 e gravando em aquivo, o resultado. Embora o módulo BeautifulSoup tenha sido chamado (linha 2), não foi usado neste código.
As Figuras 4 e 5 exibem trechos do arquivo gerado pelo código da Figura 3. O arquivo foi modificado manualmente para apresentar de forma clara a hierarquia dos marcadores da linguagem HTML, hierarquia esta, que interessa ao BeautifulSoup.
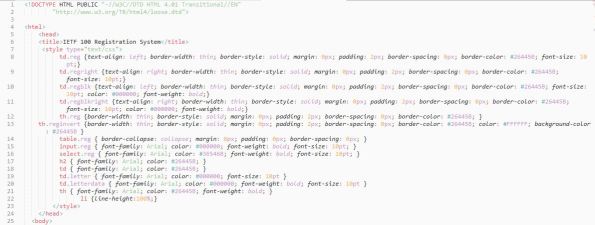
Figura 4. Trecho inicial do conteúdo capturado. Este cabeçalho não tem nenhum valor para o objetivo desejado.
A Figura 4 exibe o cabeçalho do arquivo e o marcador a partir do qual estão as informações que interessam ao objetivo a ser conseguido, usando o BeautifulSoup.
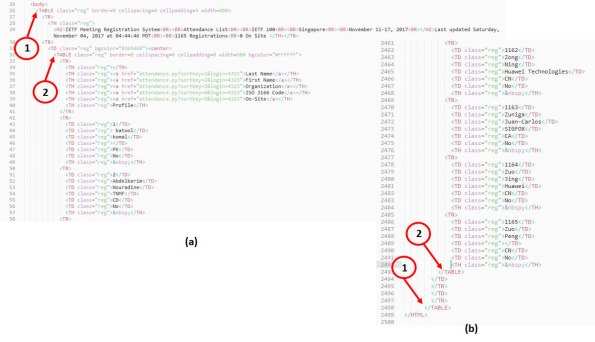
Figura 5. Em (a) mostra o inicio do trecho que interessa começando no segundo, exceto o cabeçalho. Em (b), o final do arquivo exibindo onde terminam os respectivos marcadores.
A solução de gravar o documento HTML lido pelo requests, para uma análise da hierarquia, não é a única. Alguns navegadores possuem recursos para tal análise. Por exemplo, o Firefox possui o HttpFox3, muito interessante, como pode-se ver na Figura 6.
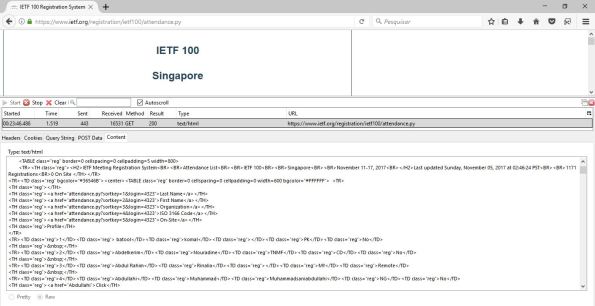
Figura 6. O HttpFox do Firefox, em ação.
O recurso Inspecionar do Chrome (do Opera, também) tem um visual e facilidades adicionais bastante atrativos, como mostra a Figura 7.
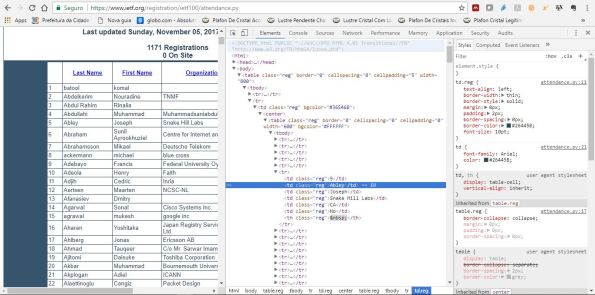
Figura 7. O recurso Inspecionar do Chrome possui vantagens adicionais e visual apropriado para a análise humana, da hierarquia.
Como se sabe que há diferenças nas páginas dos diferentes encontros (pelo menos encontramos diferenças entre o IETF 72 e o IETF 100, usaremos o Inspecionar do Chrome para resolver estas dúvidas.
Capturando as informações
Voltemos à Figura 5. A segunda <table> tem o cabeçalho formado pela primeira <tr> seguida por marcadores <th> e na sequência, até o final, os marcadores <tr> contem seis marcadores <td> seguidas por um marcador <th>.
A Figura 8 exibe o código Python do resultado final para captura dos dados dos inscritos no IETF 100. A reunião está indicada na linha 57. O trecho acrescentado para a captura corresponde à função analisa_html, compreendendo as linhas 26 a 52.

Figura 8. Código 02: aplicando o Beautiful Soup sobre o arquivo HTML obtido pelo código da Figura 3, considerando que se deseja o conteúdo do segundo marcador <table>.
Na linha 29 está a chamada do Beautiful Soup para a captura de todo o conteúdo da página de inscritos no encontro do IETF 100. Na linha 31, o método find_all é executado para encontrar dentro do segundo marcador <table> (observar o índice), todas as ocorrências do marcador <tr> (um outro find_all). Este método find_all retorna uma lista (razão do índice [1] no <table>, já que o primeiro marcador <table> ([0]), não interessa. O for garante que a cada interação, a variável row tenha os marcadores <td> e <th> do marcador <tr>. Para cada row aplica-se, na linha 32, o find_all construindo uma lista (pTD) de seis (6) marcadores <td>. Por garantia, um if verifica se o tamanho da lista pTD é 6, para seguir à frente. A primeira coisa a fazer é obter, ainda de row, o marcador <th>. executando o método find, pois sabe-se que há somente um marcador <th> em row, que na linha 34 coloca na variável profile, o texto do marcador <th>. Se profile é a palavra Click, tem-se uma URL, em um marcador a. Isto está sendo feito nas linhas 36-39. O trecho de código das linhas 41-48, monta um dicionário e concatena cada row obtido na interação do for da linha 31.
Para terminar, o Pandas é usado (chamada na linha 3, para construir a tabela com base no dicionário construído pela função analisa_html e grava uma planilha Excel.
Considerações e recomendações
- Na comparação feita entre o IETF 72 e o IETF 100 há diferenças no número de colunas, ou no número de marcadores <td> e/ou <th> dentro dos marcadores <tr> (na lista row).
- Feita a alteração proposta no item anterior, na rotina principal basta um loop de 72 a 100.
- Os encontros passados são invariáveis. Isto é, não há inconveniência que os dados estejam localmente. Só o encontro atual é variável e a recomendação é tratá-lo de forma diferenciada.
- Com todos os encontros acessíveis (remotamente ou localmente) é possível responder questões tais como: fulano de tal participou de quantos eventos do IETF? Quais? Remotamente ou “on site“?
- Expandir as estatísticas para todos os países é uma opção útil.
- Disposição dos dados de forma a facilitar seu uso em tarefas que envolvam aprendizagem de máquina, por exemplo
Referências
-
- Leonardo Richardson. Beautiful Soup Documentation. Disponível em https://www.crummy.com/software/BeautifulSoup/bs3/documentation.html. Acessado em 05/11/2007.
- Beautiful Soup Documentation. https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- https://addons.mozilla.org/pt-BR/firefox/addon/httpfox/
