Archive
WordIETF
Introdução
Este texto evolui as preocupações, grosso modo, em dar “inteligência” aos agentes (ou IEs – Intelligents Elements} do modelo AEASD (Autonomous Elements Architecture for Specific Domains), cuja origem foi na dissertação de mestrado e em discussões posteriores (Braga-Filho, 2015) (Braga; Omar; Granville, 2015).
Trata-se de uma evolução, e natural aperfeiçoamento, da contextualização e da maneira de enxergar o problema. É um processo de aprendizagem, contínuo, permanente e natural, na vida de um pesquisador. Como a visão de Charles Darwin1, na sua celebrada e incontestável teoria. Se eu vivesse eternamente, chegaria a um consenso preciso, sobre a questão principal. Não sendo eterno, a contribuição pode interessar aos mais jovens.
A Figura 1 do meu texto “Preparando as RFCs para o UIMA” (https://ii.blog.br/2016/01/08/preparando-as-rfcs-para-o-uima/) sofreu uma pequena alteração e apresenta-se como a Figura 1, a seguir.
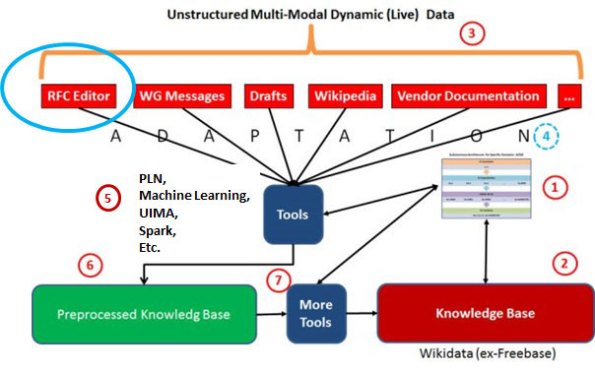 Figura 1. Novo modelo global.
Figura 1. Novo modelo global.
O que mudou foram as ferramentas (item 5, na figura). O Apache UIMA não é a única ferramenta disponível. Em algumas etapas, mas simples, ele é dispensável. Existem muitas outras! O que torna mais complexo, o tratamento de textos, um assunto muitíssimo difícil, como falam inúmeros autores. Com a linguagem natural nem se fala. Basta ouvir o pensamento de Noam Chomsky1 de que a linguagem natural não constitui um domínio sobre o qual se podem construir teorias científicas coerentes, como escreve Neil Smith2 em seu longo prefácio do “Novos horizontes no estudo da linguagem e da mente” (Chomsky, 2005).
Trata-se neste texto, portanto, incorporar outras reflexões e mostrar a necessidade de se criar um dicionário léxico sobre as RFCs, como o objetivo de facilitar os trabalhos futuros. Este dicionário, em um domínio específico (sobre as RFCs) é similar ao WordNet3, que se nomeou de WordIETF.
Contextualização
Resumindo, o conjunto de dados (textos não estruturados), isto é, o corpora que se deseja incluir no projeto é mostrado na Figura 2.
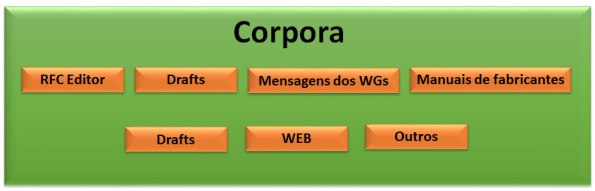 Figura 2. Corpora que interessa ao projeto final e que deve ser tratado.
Figura 2. Corpora que interessa ao projeto final e que deve ser tratado.
Por razões de simplicidade, os exercícios preliminares serão reduzidos a um único corpus, como mostra a Figura 3

Figura 3. Corpus sob o qual a experiência preliminar será feita.
Simplificando, fica mais fácil seguir a proposta mostrada na Figura 4, que mostra a evolução atual do que se tem em mente, para o futuro.
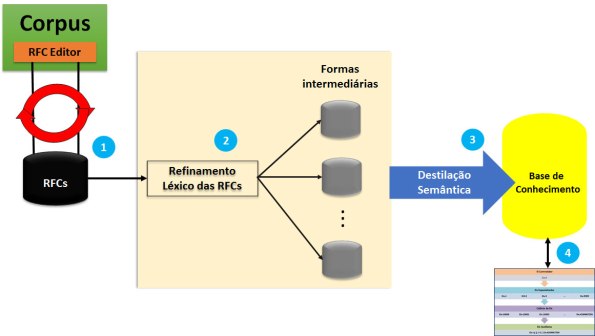
Figura 4. A atual evolução do modelo e as questões de pesquisa envolvidas: (2), (3) e (4).
O item (1) da figura acima está desenhado na Figura 2 do texto “Preparando as RFCs para o UIMA” (https://ii.blog.br/2016/01/08/preparando-as-rfcs-para-o-uima/). O item (2) representa uma das três questões de pesquisa que, de imediato, leva à criação de um dicionário léxico, WordIETF, consignado a partir do corpus, parte do RFC Editor4.
Como estabelecer o WordIETF
Em um livro bastante interessante sobre processamento de textos (Ingersoll; Morton; Farris, 2013), ferramentas do Apache são indicadas: Hadoop5, Lucene+Solr6 com o PyLucene, Mahout7 e o openNLP8. Tais ferramentas são, realmente, suficientes para resolver desafios no domínio de um texto, como mostra a Figura 5.
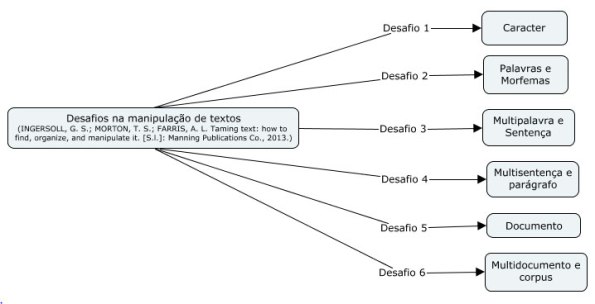
Figura 5. Desafios na mantipulação de textos.
O UIMA já foi parcialmente testado e as outras propostas da Apache serão verificadas. A Python, com o seu NLTK (Natural Languange Tool Kit), permite sem maiores esforços, a construção do WordIETF e resolver os desafios da Figura 5. Oportunamente serão descritas as experiências.
Uma outra ferramenta, que pode ser até mesmo complementar é o Mathematica4. Pode o Mathematica resolver os desafios e contribuir para a construção do WordIETF? A resposta é sim, com veremos em novos documentos mais à frente.
Conclusões
Trata-se de um projeto de pesquisa que exige a construção de um dicionário léxico, o WordIETF. Observa-se a necessidade de cooperação e contribuições de eventuais interessados.
Uma das maneiras de receber colaboração e contribuições é a divulgação no âmbito do IETF e de outras comunidades interessadas. Neste sentido, caso haja tempo hábil será enviado um I-D para o IETF 96 (Berlim), em julho próximo.
Resultados parciais e dificuldades encontradas, evolução e outras informações úteis serão postas neste blogue.
Referências
BRAGA-FILHO, L. J. Modelo para Implementação de Elementos Inteligentes em
Domínios Restritos da Infraestrutura da Internet. Dissertação (Mestrado) — Universidade Presbiteriana Mackenzie, São Paulo, SP, 8 2015.
BRAGA, J.; OMAR, N.; GRANVILLE, L. Z. Uma proposta para o uso de elementos
inteligentes em domínios restritos da infraestrutura da internet. In: Anais CSBC, WPIETFIRTF. Recife, Pernambuco, Brasil: [s.n.], 2015
CHOMSKY, N. Novos horizontes no estudo da linguagem e da mente. [S.l.]: Unesp, 2005.
INGERSOLL, G. S.; MORTON, T. S.; FARRIS, A. L. Taming text: how to find, organize,
and manipulate it. [S.l.]: Manning Publications Co., 2013.
1. https://pt.wikipedia.org/wiki/Charles_Darwin
2. https://en.wikipedia.org/wiki/Neil_Smith_%28linguist%29
3. https://wordnet.princeton.edu/
4. https://www.rfc-editor.org/
5. http://hadoop.apache.org/
6. http://lucene.apache.org/index.htm
7. http://mahout.apache.org/
8. https://opennlp.apache.org/index.html
9. http://www.wolfram.com/
