Archive
Preparando as RFCs para o UIMA
Introdução
Uma vez entendido o UIMA segue a aprendizagem sobre ele. Olhando primeira figura do texto Instalação do Apache UIMA (Apache UIMA Installation), vê-se o conjunto de material não estruturado a ser analisado, reproduzida na Figura 1, com ênfase no repositório do RFC Editor, onde repousam os principais documentos do IETF.
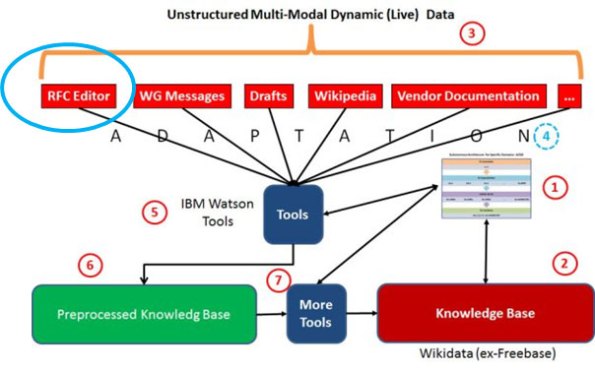
Figura 1. O repositório das RFCs. Primeira base não estruturada a ser analisada pelo UIMA.
Como trabalhar com o repositório das RFCs
RFCs não possuem data e hora marcadas para aparecer e, estão em um formato que deve ser normalizado (brancos, figuras em texto, autores, diferenças de padrões de escrita, etc.), para adaptar-se ao UIMA ou outra aplicação. Este processo de normalização é, na verdade uma “arrumação” sobre os dados de entrada e possui as característica descritas por Wickham (2014)1. Portanto é necessário, um pré-processamento, no qual estas duas questões serão resolvidas. A Figura 2 apresenta um modelo preliminar a ser seguido.
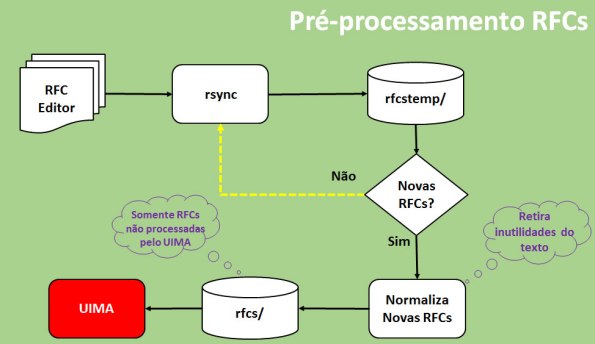
Figura 2. O pré-processamento das RFCs.
O próprio RFC Editor recomenda um mecanismo2 de recuperação de RFCs usando o rsync, uma ferramenta disponível nos sistema a la Unix e também, no Windows. Como mostra a Figura 2, o rsync trás a base do RFC Editor para o diretório rfstemp/ local, de forma incremental, como se desejava. Sobre este diretório, um programa em Python (denominado preprocess.py) é executado periodicamente e, sempre, executa o rsync, transferindo as novas RFCs para o diretório rfcs/, as quais são consumidas pelo UIMA. A Figura 3 mostra o exemplo de uma execução do rsync, no Windows 10, via prompt e uma nova RFC disponível (rfc7715.txt). Naturalmente, esta execução não foi a primeira vez, oportunidade em que isto é, o diretório rfstemp/ já tinha sido populado com TODAS as RFCs.
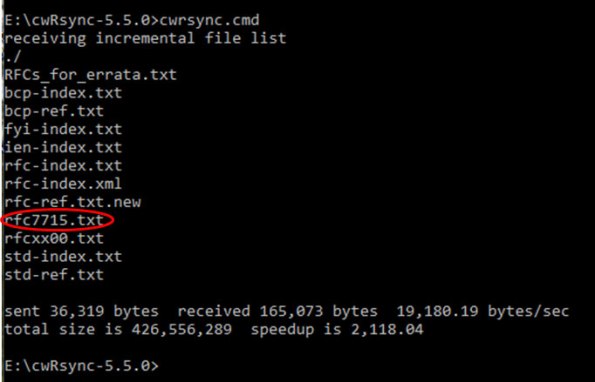
Figura 3. Execução do rsync e a disponibilidade de uma nova RFC enfatizada em vermelho.
A periodicidade de execução do programa preprocess.py é feita, automaticamente, através do cron (um processo, também, disponível para o Windows). Ele preserva a informação sobre a última RFC atualizada, captura as novas, normalizando e colocando-as no diretório de entrada para o UIMA (rfcs/). O processo de normalização é simples, retirando tudo o que é texto inútil de cada RFC (brancos, rodapés, etc.). Em função do UIMA, o programa preprocess.py, eventualmente, evoluirá o processo de normalização e/ou aperfeiçoará a entrada (isto é, o conteúdo do diretório rfcs/).
O UIMA, ao consumir as RFCs deixa o diretório rfcs vazio. Nas atividades do UIMA, Java é a principal linguagem, como vimos no primeiro artigo da série: Instalação do Apache UIMA (Apache UIMA Installation). O segundo artigo é uma visão geral do UIMA: Funcionamento Básico do Apache UIMA
- Wickham, H. Tidy Statistic. Journal of Statistical Software, Foundation for Open Access Statistics, v. 59, n. 10, 2014.
- https://www.rfc-editor.org/retrieve/rsync/
