Archive
Uma Fábrica de Algoritmos de Aprendizagem de Máquina baseada em Ontologia, para a Infraestrutura da Internet
Introdução
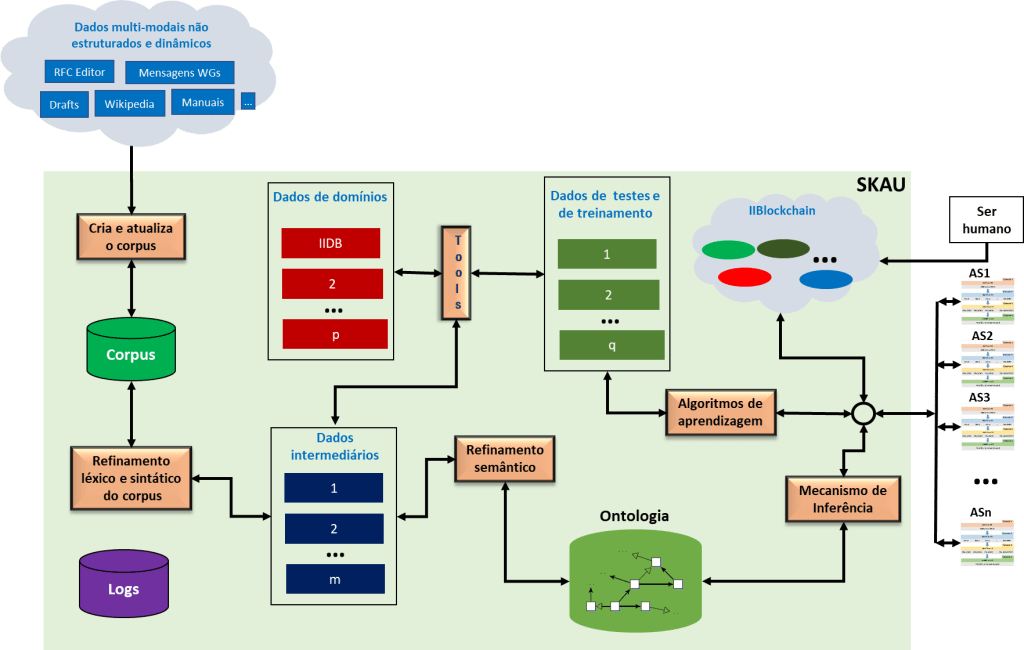
Na defesa de minha tese de doutorado (2019) foi proposto um ambiente para o desenvolvimento de uma ontologia [6], para a Infraestrutura da Internet (II). Esta ontologia teria como objetivo fornecer conhecimento para os agentes inteligentes que iriam trabalhar no domínio (restrito) da II. Tanto a ontologia como os agentes inteligentes fazem parte de um ambiente que foi denominado Structure of Knowledge Acquisition, Use, Learning, and Collaboration (SKAU) [1]. A arquitetura do SKAU pode ser visto na Figura 1.
Mais recentemente, meus colegas e eu simplificamos o ambiente SKAU para atender a um rápido desenvolvimento da ontologia, que passamos a chamar de IIOntology, de tal maneira que os testes de validação desta ontologia pudessem ser feitos através da linguagem SPARQL Protocol and RDF Query Language (SPARQL) {2, 3, 4, 5]. Esta simplificação está apresentada na Figura 2.
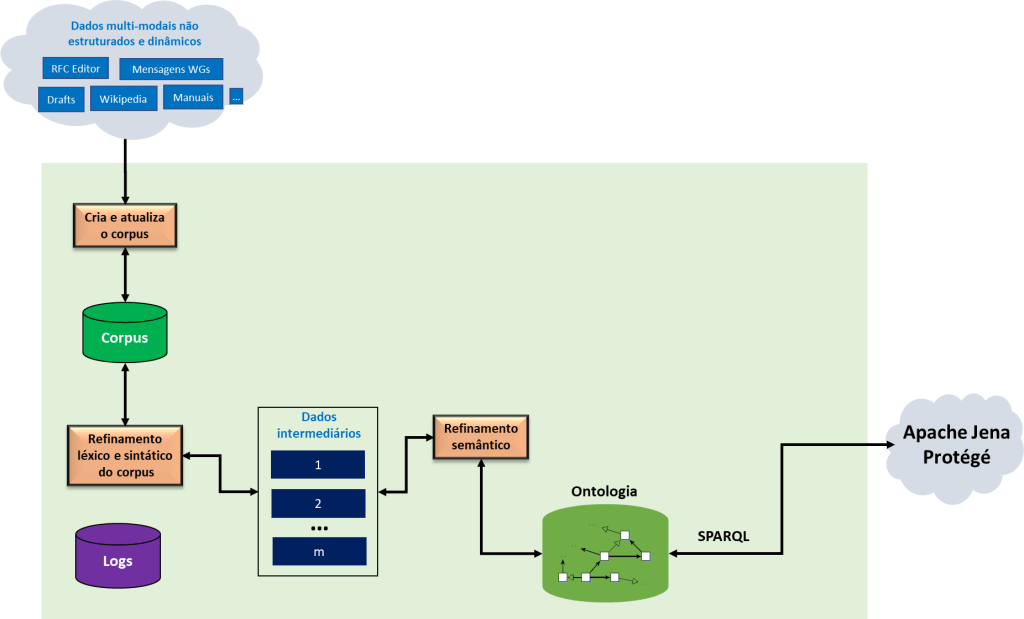
Mais recentemente, notamos notamos interesses no IRTF (a partir do RG RASPRG1) em aplicações mais efetivas de Aprendizagem de Máquina (ML) sobre as atividades do IETF e organizações associadas.
Sendo assim decidimos por ampliar o uso da ontologia do ambiente SKAU disponibilizando-a para o que denominamos de Fábrica de Algoritmos de ML e inferências, que iriam disponibilizar este conhecimento para além dos agentes inteligentes, isto é, para os interessados nas atividades da II. Foi produzida, então, a Figura 3 exibindo esta extensão.
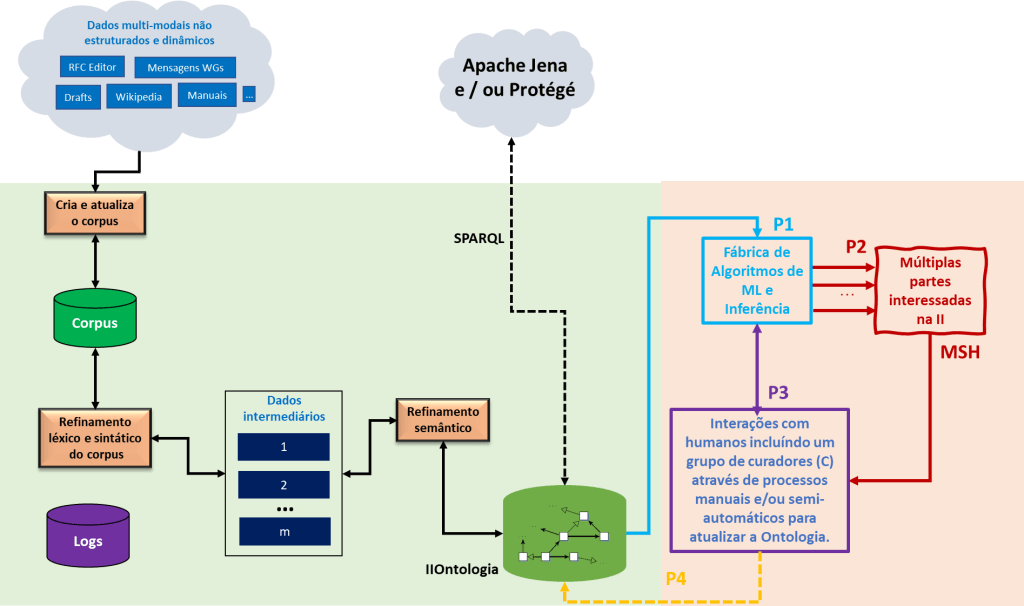
Figura 3. Ampliando o uso da IIOntology. Fonte: Ontology-based Machine Learning Algorithms for the Internet Infrastructure Domain (em preparação).
Em linhas gerais, revendo a Figura 3, no domínio da II (DII) serão capturadas informações de fontes de dados multimodais, não estruturadas e dinâmicas, a partir de dados disponíveis na Web e em outras fontes. Através de uma etapa usando processos manuais, semiautomatizados ou automatizados utilizando-se da Semantic Web Rule Language (SWRL) será construída, em um processo que nunca pára, uma ontologia a ser usada como entrada (P1) para uma fábrica de aplicações de algoritmos de ML, com o objetivo de produzir informações (P2) a diversas partes interessadas (MSH) no DII. A ontologia, através da interação com humanos e instituições (MSH) será atualizada e aperfeiçoada, incluindo o uso permanente de Curadoria (C), em P3 e P4, complementarmente ao processo de mineração durante a formação e atualização usando fontes externas.
O uso da IIOntology tornará a aplicação dos algoritmos de ML mais eficientes e menos propícios a características que produzem falsos resultados, como veremos mais a frente.
Considerações rápidas sobre a vantagens de se ter algoritmos de ML baseados em uma ontologia
Se os dados do domínio (ou o conhecimento do domínio) forem condensados em uma ontologia atualizada sistematicamente, podemos adaptar os algoritmos de aprendizado de máquina (ML) para capturar esse conhecimento sem a necessidade de um processo de treinamento completo.
Isso é possível porque:
- Ontologias fornecem uma representação formal e estruturada do conhecimento do domínio. Isso facilita a extração de informações relevantes para os algoritmos de ML.
- Ontologias podem ser atualizadas sistematicamente para refletir as mudanças no conhecimento do domínio. Isso garante que os algoritmos de ML estejam sempre atualizados com as últimas informações.
- Existem diversas técnicas de aprendizado de máquina que podem ser utilizadas para aprender a partir de ontologias. Essas técnicas podem ser adaptadas para diferentes tipos de tarefas, como classificação, predição e agrupamento.
Ao utilizar ontologias para adaptar algoritmos de ML, podemos obter diversos benefícios:
- Redução do tempo e esforço necessários para treinar os algoritmos.
- Melhoria da precisão e robustez dos algoritmos.
- Maior facilidade de interpretação dos resultados dos algoritmos.
- Possibilidade de desenvolver sistemas de ML mais escaláveis e adaptáveis.
No entanto, é importante ressaltar que o uso de ontologias não elimina completamente a necessidade de treinamento. Em alguns casos, pode ser necessário realizar um treinamento fino dos algoritmos para adaptá-los a um conjunto de dados específico ou para otimizar seu desempenho.
Em resumo, o uso de ontologias para adaptar algoritmos de ML é uma estratégia promissora para reduzir a necessidade de treinamento e melhorar o desempenho dos sistemas de ML.
Benefícios de Usar Ontologias em Algoritmos de Aprendizado de Máquina (ML)
A Tabela abaixo exibe alguns benefícios e respectivos detalhes sobre o uso de algoritmos de ML sobre ontologias.
| Benefício | Descrição |
|---|---|
| Melhor Compreensão do Domínio: | As ontologias fornecem uma representação formal e estruturada do conhecimento do domínio, facilitando a compreensão dos conceitos, relações e hierarquias presentes no domínio. Isso permite que os algoritmos de ML sejam projetados de forma mais eficaz e precisa, levando a um melhor desempenho. |
| Maior Eficiência no Treinamento: | Ao utilizar ontologias, os algoritmos de ML podem aprender com menos dados, pois a ontologia fornece informações pré-existentes sobre o domínio. Isso significa que o tempo e o esforço necessários para treinar os algoritmos podem ser significativamente reduzidos. |
| Melhoria na Precisão dos Resultados: | As ontologias garantem a consistência e coerência das informações utilizadas pelos algoritmos de ML, o que reduz a probabilidade de erros e aumenta a confiabilidade dos resultados. Além disso, as ontologias podem ser atualizadas sistematicamente para refletir as mudanças no conhecimento do domínio, garantindo que os algoritmos estejam sempre atualizados com as últimas informações. |
| Maior Facilidade de Interpretação dos Resultados: | As ontologias facilitam a interpretação dos resultados dos algoritmos de ML, pois fornecem um contexto para os dados e permitem que os resultados sejam explicados em termos de conceitos do domínio. Isso é crucial para a construção de sistemas de ML confiáveis e transparentes. |
| Reusabilidade do Conhecimento: | As ontologias permitem a reutilização do conhecimento em diferentes aplicações de ML, pois fornecem uma representação comum do domínio que pode ser compartilhada entre diferentes algoritmos e sistemas. Isso facilita o desenvolvimento de sistemas de ML mais eficientes e escaláveis. |
| Redução do Viés: | As ontologias podem ser utilizadas para identificar e mitigar vieses nos dados de treinamento, o que leva a resultados mais justos e equitativos. Isso é particularmente importante para aplicações de ML que têm impacto na sociedade, como sistemas de tomada de decisão ou análise de dados. |
Adicionalmente, o uso de ontologias pode contribuir para a mitigação de características especiais, que produzem falsos resultados e inerentes aos modelos, como o esquecimento catastrófico e a alucinação em algoritmos de deep learning (DL).
Eis o significado destas características, relativamente comuns nos algoritmos de Large Language Models:
- Esquecimento Catastrófico: Ocorre quando um modelo de DL “esquece” o conhecimento adquirido durante o treinamento inicial ao aprender novas informações. Isso pode levar a um declínio significativo no desempenho do modelo.
- Alucinação: Ocorre quando um modelo de DL gera resultados falsos ou inventados, não presentes nos dados de treinamento. Isso pode levar a decisões erradas e interpretações incorretas.
Conclusões
Este é um projeto de pesquisas amplo e multidisciplinar que precisa envolver grupos interessados de várias instituições e tem um ambiente colaborativo preparado para receber estes interessados, aqui.
Referências:
[1] Juliao Braga. Ambiente para Aquisição de Conhecimento por Agentes em Domínios Restritos na Infraestrutura da Internet. PhD Thesis, Instituto Superior Tecnico & Universidade Presbiteriana Mackenzie, 2019. DOI: https://doi.org/10.31237/osf.io/nzmtf.
[2] SPARQL 1.1 Overview. https://www.w3.org/TR/sparql11-overview/, 2013. Accessed: 2024-03-
16.
[3] SPARQL 1.1 Query Language. https://www.w3.org/TR/sparql11-query/, 2013. Accessed: 2024-
03-16.
[4] SPARQL New Features and Rationale. https://www.w3.org/TR/sparql-features/, 2010. Accessed:
2024-03-16.
[5] SPARQL Query Language for RDF. https://www.w3.org/TR/rdf-sparql-query/, 2008. Accessed:
2024-03-16
[6] Juliao Braga, Francisco Regateiro, Itana Stiubiener, and Juliana C Braga. A partial ontology on DAOs, built manually. In Paola Cantarini, editor, IA e Espistemologias do Sul, pages 1–29. Editora Lumen Juris Direito, Sao Paulo, SP Brazil, 2023. DOI: https://doi.org/10.31219/osf.io/kgfxt.
