Archive
Considerações preliminares de como planejar a implementação de uma Máquina Virtual (VM), na nuvem
Recentemente, por força de um projeto que estou envolvido contratei uma máquina virtual (VM). Durante o processo de contratação, a única coisa que tinha conhecimento é de onde estava a minha VM. A Figura 1, exibe onde minha VM se encontra.

Poucos dias depois, me informaram que a VM tinha um número IPv4. Infelizmente, não um IPv6. Não ter um IPv6 é uma falha técnica e comercial gravíssima. Mas de qualquer forma, ter um IPv4 esclareceu exatamente onde minha VM estava. Ela estava instalada em algum servidor fisicamente localizado em ambiente controlado por um Sistema Autônomo, qualquer, de número n (ASn). Provavelmente em um servidor instalado em algum hack. A Figura 2 ilustra este pensamento.

Este sistema autônomo ASn está conectado a um ou mais outros Sistemas Autônomos, que por sua vez estão conectados a outros tantos ASes e assim sucessivamente. Estas conexões de Sistemas Autônomos formam o que conhecemos como Internet (com I maiúsculo). Com a diminuição da oferta de IPv4, e a disponibilidade, sem restrições, do IPv6, a Internet está dividida em três tipos: Internet IPv4, Internet IPv6 e Internet IPv4+IPv6 (pilha dupla). A Figura 3 mostra os três tipos de Internet.
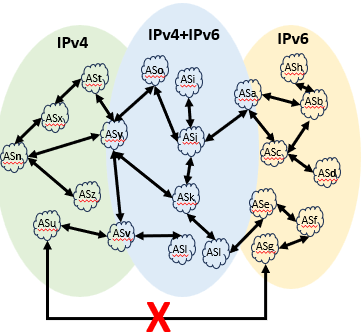
A tendência é a Internet IPv6 prevalecer sobre as demais. Mas, enquando isto, a minha VM está inacessível pela Internet IPv6!
Então, a VM está na Internet e, portanto acessível por qualquer pessoa do mundo (claro, que tenham IPv4). Por razões práticas e para o planejamento da VM, a Figura 4 classifica claramente os interessados em acessar a minha VM.
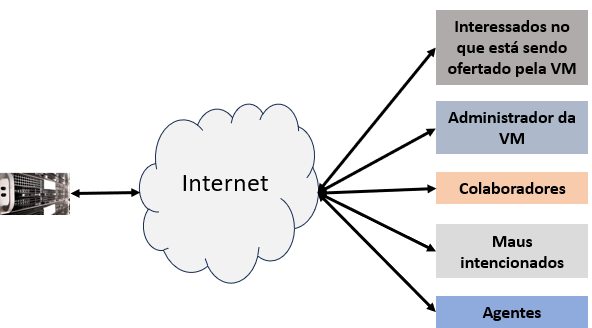
Caracterizando cada um dos interessados:
- Interessados no que está sendo ofertado pela VM: Estes interessados somente usarão os recursos disponíveis pelo servidor Apache e facilidades associadas. Prativamente usando navegadores, aplicações em desktop ou em equipamento móvel (telefone celular, por exemplo). São seres humanos que podem estar em qualquer localização, no mundo.
- Administrador da VM: Terá acesso a todos os recursos disponíveis na VM e, portanto, tem de estabelecer conexões seguras, esteja onde estiver e de múltiplas formas.
- Colaboradores: Pessoas autorizadas em executar tarefas específicas, orientadas ou não, de qualquer lugar do mundo. Seu acesso pode ser de múltiplas formas seguras: ssh, ftp, vpn.
- Maus intencionados: Seres humanos com terceiras intenções de acessar a VM devido interesses escusos ou não. Eles devem ter seu acesso negado.
- Agentes: Artefatos automáticos e/ou inteligentes, com os mais divesos interesses. Seletivamente, o acessso destes dispositivos devem ser negados ou não.
Com base nestas características de acesso, a VM tem de ser implementadas com todos os possíveis recursos para que a VM tenha funcionamente apropriado. Adicione o fato de que mecanimos de backup devem ser instalados, também.
A proposta sobre os recursos a serem instalados e de que maneira, será analisado no próximo artigo.
