Identificadores de Recursos usados na Internet
São quatro, os indicadores de recursos usados na Internet, para identificar ou localizar recursos na Web ou em outros sistemas de informação: URI, IRI, URL e URN. Recurso é qualquer coisa que possa ser identificada e referenciada, como por exemplo, documentos, imagens, vídeos, serviços web, bases de dados, pessoas, lugares, conceitos, etc.
Há uma hierarquia bem definida entre estes quatro recursos, a qual pode ser vista na figura abaixo.
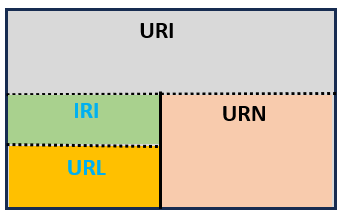
de indicadores de recursos
URI
Um Uniform Resource Identifier (URI) fornece um meio simples e extensível para identificar um
recurso. Esta especificação de sintaxe e semântica de URI é derivada de conceitos introduzidos pela iniciativa de informação global da WWW, cujo uso desses identificadores data de 1990 e é descrito em Berners-Lee (1994). A sintaxe é projetada para atender às recomendações estabelecidas em Kunze (1995) e Sollins and Masinter (1994) (Berners-Lee, Fielding and Masinter, January 2005).
Apesar de estarmos habituados com o termo URL, Hansen, Hardie and Masinter (2006) caracteriza que documentos recentes têm usado o termo URI para todos os identificadores de recursos, evitando o termo URL e reservando o termo URN explicitamente para aqueles URIs usando o nome do esquema urn (Saint-Andre and Klensin, 2017). Os namespaces URN são específicos do esquema urn (Saint-Andre and Klensin, 2017)).
Um namespace, ou espaço de nomes, é um conceito fundamental em programação e desenvolvimento de software que permite organizar e agrupar elementos relacionados, como classes, funções e variáveis, em um contexto específico. Ele atua como um contêiner que contém um conjunto de identificadores únicos, evitando conflitos de nomes e facilitando a organização e a manutenção do código
IRI
Um Internationalized Resource Identifier (IRI) é uma sequência de caracteres do Conjunto Universal de Caracteres (Unicode/ISO 10646) e um subconjunto do URI (Duerst and Suignard, 2005b) (Thaler, Hansen and Hardie, 2015). IRIs são usados no lugar de URIs para identificar recursos.
URL
É o identificador mais conhecido, que representa uma cadeia de caracteres compacta para identificar a localização de um recurso disponível na Web. São chamadas de Uniform Resource Locators (URLs) (Berners-Lee, Masinter and McCahill, 1994) (Kerwin, 2017).
URN
Um Uniform Resource Name (URN) (Saint-Andre and Klensin, 2017) é um URI (Berners-Lee, Fielding and Masinter, January 2005) que é atribuído sob o esquema URI urn e um namespace URN específico, com a intenção de que o URN seja um identificador de recurso persistente e independente de localização. Um namespace URN é uma coleção de tais URNs, cada um dos quais é (1) único, (2) atribuído de forma consistente e gerenciada e (3) atribuído de acordo com uma definição comum. (Alguns namespaces URN criam nomes que existem apenas como URNs, enquanto outros atribuem URNs com base em nomes que já foram criados em sistemas de identificadores não URN, como ISBNs (Hakala and Walravens, 2001), ISSNs (Rozenfeld, 2001) ou RFCs (Moats, 1999).)
A atribuição de URNs é feita por uma organização (ou, em alguns casos, de acordo com um algoritmo ou outro processo automatizado) que foi formalmente delegado a um namespace URN dentro do esquema urn (por exemplo, um URN no namespace example pode ser do formato urn:example:foo (Saint-Andre, 2013)).
Os URNs são projetados para serem identificadores permanentes. Um dos desafios é garantir que esses identificadores permaneçam válidos e acessíveis ao longo do tempo, mesmo que os recursos referenciados mudem de localização ou sejam descontinuados.
Usos do URN
Em IANA (2024) há uma extensa lista de URNs e suas respectivas referências. Abaixo, uma relação de exemplos de URNs:
• ISBN: urn:isbn:978-3-16-148410-0 – Este é um identificador único para livros, permitindo que cada título seja referenciado de maneira consistente (International ISBN Agency, 2024).
• ISSN: urn:issn:1535-3613 – Utilizado para identificar publicações periódicas, como revistas e jornais (ISSN International Centre, 2024).
• DOI: urn:doi:10.1000/xyz123 – Um identificador utilizado para artigos acadêmicos e outros tipos de publicações digitais, garantindo que possam ser referenciados de forma persistente (DOI Foundation, 2024).
• UUID: urn:uuid:123e4567-e89b-12d3-a456-426614174000 – Um identificador universalmente único que pode ser utilizado em diversas aplicações, incluindo sistemas de banco de dados e serviços web (Davis, Peabody and Leach, 2024).
• URN para Recursos de Redes: urn:ietf:rfc:3986 – Referencia um documento específico do IETF, que descreve a sintaxe de URIs (Moats, 1999)..
Referências
- [Berners-Lee et al. January 2005] BERNERS-LEE, T. ; FIELDING, R. ; MASINTER, L.: Uniform Resource Identifier (URI): Generic Syntax / RFC Editor. January 2005. – Research report. (RFC3986.) (DOI: 10.17487/RFC3986).
- [Berners-Lee 1994] BERNERS-LEE, T.: Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World Wide Web / RFC Editor. June 1994. – Research report. RFC1630. (Status: INFORMATIONAL) (Stream: Legacy) (DOI: 10.17487/RFC1630). Acessado em 15/08/2024.
- [Berners-Lee et al. 1994] BERNERS-LEE, T. ; MASINTER, L. ; MCCAHILL, M.: Uniform Resource Locators (URL) / RFC Editor. December 1994. – Research report. RFC1638. (Obsoleted-By RFC4248, RFC4266) (Updated-By RFC1808, RFC2368, RFC2396, RFC3986, RFC6196, RFC6270, RFC8089) (Status: PROPOSED STANDARD) (Stream: Legacy) (DOI: 10.17487/RFC1738). Accessed: 15/08/2024.
- Davis et al. 2024] DAVIS, K. ; PEABODY, B. ; LEACH, P.: Universally Unique IDentifiers (UUIDs) / RFC Editor. May 2024. – Research report. RFC9562. (Obsoletes RFC4122) (Status: PROPOSED STANDARD) (Stream: IETF, Area: art, WG: uuidrev) (DOI: 10.17487/RFC9562). Accessed: 16/08/2024.
- [DOI Foundation 2024] DOI FOUNDATION: Digital Object Identifier (DOI). 2024. – URL https://www.doi.org/. – Accessed: 2024-08-16
- [Hakala and Walravens 2001] HAKALA, J. ; WALRAVENS, H.: Using International Standard Book Numbers as Uniform Resource Names / RFC Editor. October 2001. – Research report. RFC3187. (Obsoleted-By RFC8254) (Status: HISTORIC) (Stream: Legacy) (DOI: 10.17487/RFC3187). Accessed: 15/08/2024.
- [IANA 2024] IANA: Uniform Resource Names (URN) Namespaces. 2024. – URL https://www.iana.org/assignments/urn-namespaces/urn-namespaces.xhtml. – Last Updated: 2024-05-29.
- [International ISBN Agency 2024] INTERNATIONAL ISBN AGENCY: International ISBN Agency. – URL https://www.isbn-international.org/. – Accessed: 2024-08-16.
- [ISSN International Centre 2024] ISSN INTERNATIONAL CENTRE: ISSN International Centre. – URL https://www.issn.org/. – Accessed: 2024-08-16.
- [Kerwin 2017] KERWIN, M.: The “file”URI Scheme / RFC Editor. February 2017. – Research report. RFC8089. (Updates RFC1738) (Status: PROPOSED STANDARD) (Stream: IETF, Area: art, WG: appsawg) (DOI: 10.17487/RFC8089). Accessed: 15/08/2024.
- [Kunze 1995] KUNZE, J.: Functional Recommendations for Internet Resource Locators / RFC Editor. February 1995. – Research report. RFC1636. (Status: INFORMATIONAL) (Stream: Legacy) (DOI: 10.17487/RFC1736). Acessado em 15/08/2024.
- [Moats 1999] MOATS, R.: A URN Namespace for IETF Documents / RFC Editor. August 1999. – Research report. RFC2648. (Updated-By RFC6924, RFC9141) (Status: INFORMATIONAL) (Stream: IETF, Area: app, WG: urn) (DOI: 10.17487/RFC2648). Accessed: 15/08/2024.
- [Rozenfeld 2001] ROZENFELD, S.: Using The ISSN (International Serial Standard Number) as URN (Uniform Resource Names) within an ISSN-URN Namespace / RFC Editor. January 2001. – Research report. RFC30447. (Obsoleted-By RFC8254) (Status: HISTORIC) (Stream: Legacy) (DOI: 10.17487/RFC3044). Accessed: 15/08/2024.
- [Saint-Andre and Klensin 2017] SAINT-ANDRE, P. ; KLENSIN, J.: Uniform Resource Names (URNs) / RFC Editor. April 2017. – Research report. RFC8141. http://www.rfc-editor.org/rfc/rfc81416.txt. (Obsoletes RFC2141, RFC3406) (Status: PROPOSED STANDARD) (Stream: IETF, Area: art, WG: urnbis) (DOI: 10.17487/RFC8141). Accessed: 13/08/2024.
- [Saint-Andre 2013] SAINT-ANDRE, P.: A Uniform Resource Name (URN) Namespace for Examples / RFC Editor. May 2013. – Research report. RFC6996. (Also BCP0183) (Status: BEST CURRENT PRACTICE) (Stream: IETF, WG: NON WORKING GROUP) (DOI: 10.17487/RFC6963). Accessed: 15/08/2024
- [Sollins and Masinter 1994] SOLLINS, K. ; MASINTER, L.: Functional Requirements for Uniform Resource Names / RFC Editor. December 1994. – Research report. RFC1637. (Status: INFORMATIONAL) (Stream: Legacy) (DOI: 10.17487/RFC1737). Acessado em 15/08/2024.
- [Thaler et al. 2015] THALER, D. ; HANSEN, T. ; HARDIE, T.: Guidelines and Registration Procedures for URI Schemes / RFC Editor. June 2015. – Research report. RFC7595. (Obsoletes RFC4395) (Updated-By RFC8615) (Also BCP0035) (Status: BEST CURRENT PRACTICE) (Stream: IETF, Area: art, WG: appsawg) (DOI: 10.17487/RFC7595). Accessed: 15/08/2024
