Funcionamento Básico do Apache UIMA
Introdução
Para entender o Apache UIMA é necessário avançar sobre muitos conceitos e por meandros do inter relacionamento entre tais conceitos. A Figura 1 mostra os componentes do Apache UIMA, de forma bastante abstrata. Sobre ela segue uma abordagem, com o objetivo de facilitar a compreensão do funcionamento básico do UIMA. O documento do qual se capturou tal descrição é o UIMA Tutorial and Developers’ Guides1, Capítulo 1. A introdução em Instalação do Apache UIMA ajuda a entender onde ele se aplica.
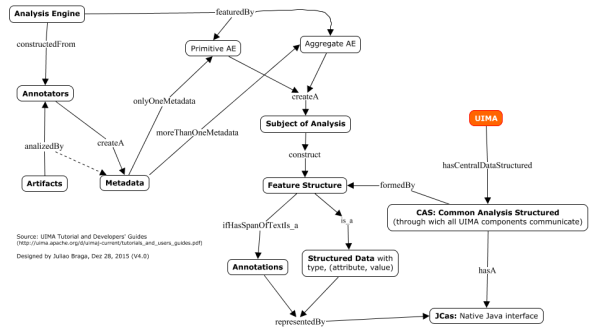
Navegando pelos componentes do UIMA
O componente central do UIMA é o CAS (Common Analysis Structure), uma estrutura de dados sobre a qual todos os outros componentes do UIMA se comunicam. Há uma interface Java chamada JCas, disponível no UIMA SDK2 que atende às demandas do CAS. O JCas permite a representação de cada Feature Structure (que faz parte do CAS), como um objeto Java.
Como o Feature Structure pertence ao CAS, então ele é uma estrutura de dados. Sua estrutura de dados é construída pelo tipo e por um conjunto de pares (atributo, valor). Esta estrutura de dados é produzida pelo AE (Analysis Engine).
O AE é um programa e parece ser o componente mais importante do UIMA, pois é ele quem agrupa as análises feitas sobre os artefatos (artifacts), nome genérico dado aos elementos (multimodais, pois podem ser texto, imagem, som, etc.) de entrada que serão analisados e, também, sobre os quais serão inferidas informações. O AEs são formados através de blocos de construção chamados Annotators, que na prática constroem dois tipos de AEs: Primitive AE e Aggregate AE.
Os Annotators produzem a chamada lógica de análise (analysis logic) e são construídas a partir da análise sobre os artefatos, as quais adicionam dados, que por razões óbvias são chamados de metadados (metadata) (dados que falam sobre artefatos). Se um AE possui um único Annotator então ele é um Primitive EA. Se, por outro lado, o EA possui um conjunto de Annotators então ele é um Aggregate AE. Os Annotators criam novas representações do texto, no formato de Sofa (Subject of Analysis), que constroem a Feature Structure. O AEs, de qualquer tipo utilizam uma interface única, compartilhada por todas as aplicações. Existem diversas facilidades disponíveis3, para a construção de Annotators.
Por fim, os AEs são incorporados, como estrutura de dados, nas Feature Structures. Se um AE contem uma informação anexada a uma parte do artefato, ele é considerado como uma annotation, enquanto os outros são Structured Data.
Vale a pena lembrar as consequências induzidas no texto: se AEs são importantes, então os Annotators, que os formam passam a ser os componentes mais importantes e por eles deve-se começar o processo de utilização do UIMA! Neste sentido e para fixar mais as ideias sobre os conceitos, eis as etapas para desenvolver um Annotator, segundo o UIMA Tutorial and Developers’ Guides1:
- Defina os tipos de CAS que o Annotator irá usar.
- Gere as classes Java para estes tipos.
- Escreva o código Java real, do Annotator.
- Crie o descritor do AE.
- Teste o Annotator.
Complementarmente, um bom começo está em Getting Started: Writing My First Apache UIMA Annotator4
-
08/01/2016 at 19:37Preparando as RFCs para o UIMA | Infraestrutura da Internet
